




Introduction
Sound therapy is one of the oldest modalities for treating tinnitus and is still widely used. Listening to an external sound masks the perception of tinnitus, and helps the individual to feel more comfortable than in a quiet environment. Various sounds, such as pure tones, narrow band noise, white noise, and notched music, have been used to shield tinnitus.1-5) Jastreboff investigated habituation of tinnitus perception by supplying an external sound at the mixing point, where the tinnitus is mixed with the shielding sound instead of completely masking the tinnitus.6) Acoustic stimulation in individuals with tinnitus can decrease the discomfort induced by tinnitus, evoke positive feelings, and induce relaxation to facilitate long-term habituation to tinnitus.7) Moreover, specially designed sounds may restore the maladapted plastic change of the auditory cortex by altering the lateral inhibition or neural synchronization.5)
The amplification of the external sound by a hearing aid (HA) not only masks the tinnitus itself, but also compensates for the hearing loss of individuals with tinnitus.8) This may facilitate restoration of the maladapted plastic change of the auditory cortex by resupplying an auditory input. Sometimes, however, the sound amplified by the HA does not mask the tinnitus fully. In some individuals, the sound is insufficient to mask the tinnitus in quiet environments, and they may not want to wear their HA in quiet conditions. Therefore, many HA manufacturers have developed combination device comprising a HA and a built-in sound generator, which produces a tinnitus-control sound (TCS). The manufacturers often provide a program to change the device from a HA-only option to a HA plus TCS option. Several studies have demonstrated better therapeutic effects on tinnitus by using the combination device (i.e., HA plus sound generator) compared with a HA alone.4,9) However, one concern about these combination devices is that the TCS may hinder the user’s speech perception; however, it is unknown whether this is the case. Several studies have revealed that tinnitus functions as a central masker that constrains the individual’s speech perception ability.10–13) Therefore, TCSs might improve speech perception by unmasking the masking effect of tinnitus on speech perception. Auditory spectral resolution and temporal resolution are fundamental aspects of speech perception. Therefore, in this work, we evaluate the effect of TCS produced by HAs with built-in sound generators on auditory spectral resolution, temporal resolution, and speech- perception ability in individuals with tinnitus and impaired hearing.
Materials and Methods
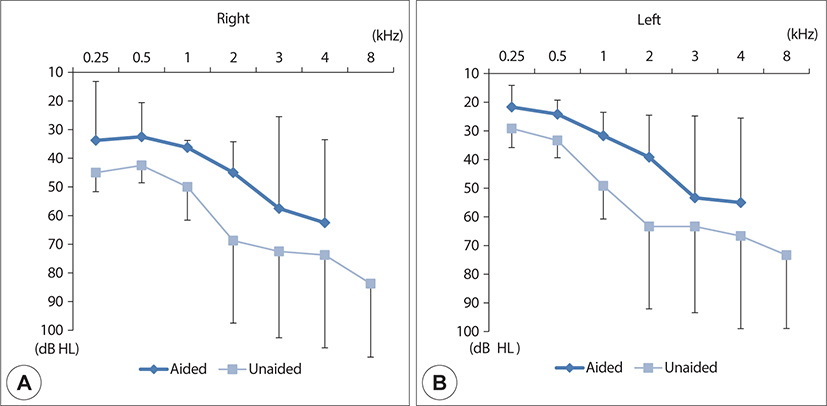
The study included 13 elderly subjects (62.38±8.44 years, seven males and six females) who had tinnitus and impaired hearing, and had been using HAs with built-in sound generators (10 unilateral HAs and three bilateral HAs) in everyday life for more than 3 months. They also used sound generators while using HAs. All of the subjects wore receiver-in-canal HAs (Unitron, Waterloo, ON, Canada). The TCS was made of white noise (170–8,500 Hz) and was set to match the mixing point similar to the loudness of tinnitus. Table 1 presents the demographics of subjects, the side and usage time of the HA, and the characteristics of tinnitus at the first visit. The mean pure tone average (PTA) of the right ears decreased from 58.44±8.56 decibels hearing loss (dB HL) without the HA to 42.81±9.92 dB HL with the HA, and the mean PTA of the left ears decreased from 52.29±15.52 dB HL to 37.08±11.42 dB HL, respectively (Fig. 1). This study was approved by the Institutional Review Board of Nowon Eulji Medical Center, Seoul, Korea, and all of the subjects provided written informed consent.
After using HAs with built-in sound generators for more than 3 months, three psychoacoustic measurements were performed to compare the results for the HA-only and HA plus TCS conditions: spectral-ripple discrimination (SRD), temporal modulation detection (TMD), and speech recognition threshold (SRT) in noise. The SRD test evaluated spectral resolution by measuring the subject’s ability to discriminate a reversal in the phase of a ripple shape. TMD evaluated the subject’s sensitivity to the temporal envelope by discriminating modulated noise from steady noise. The TMD test was conducted with modulation noises at 10 and 100 Hz. To measure the SRT, equally difficult spondee words, spoken by a male speaker, were presented in the presence of speech-shaped, steady noise. The test are described in more detail in the Supplementary Procedures (Appendix 1). The stimuli were presented at 65 dBA. The stimuli were routed through an audiometer (Madsen Astera 2, GN Otometrics, Taastrup, Denmark) and presented by a loudspeaker placed 1 m in front of the subjects. All tests were conducted in a sound-attenuating booth (Acoustic systems, Austin, TX, USA).
SPSS version 10 (SPSS, Chicago, IL, USA) was used for all statistical analyses. The results of the three tests were between the HA-only and HA plus TCS conditions using Wilcoxon’s signed rank test, as appropriate. Correlations between the SRTs in noise and tinnitus characteristics were analyzed using Pearson’s correlation coefficient.
Results
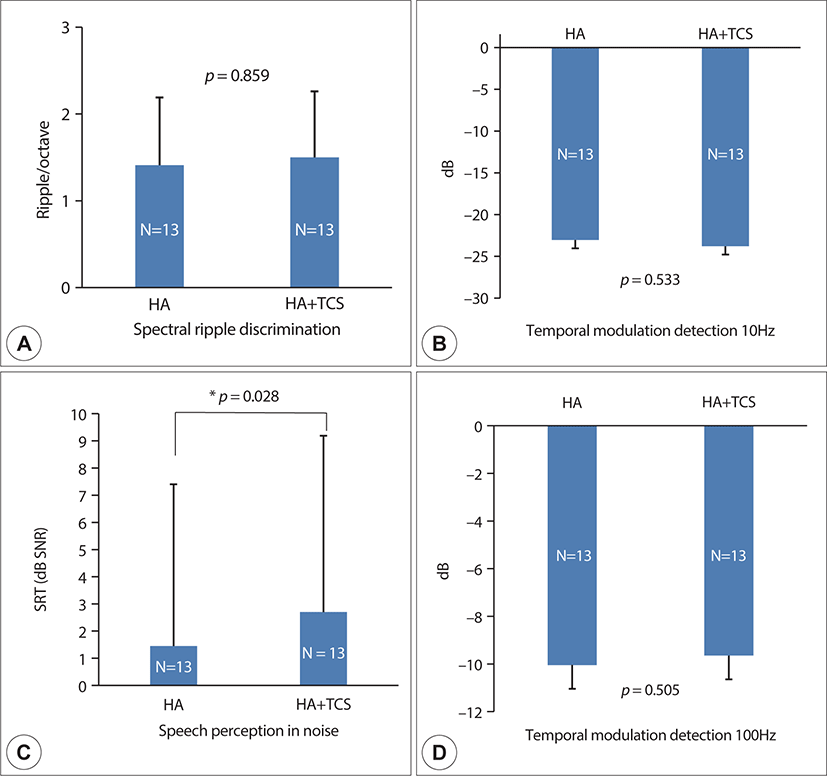
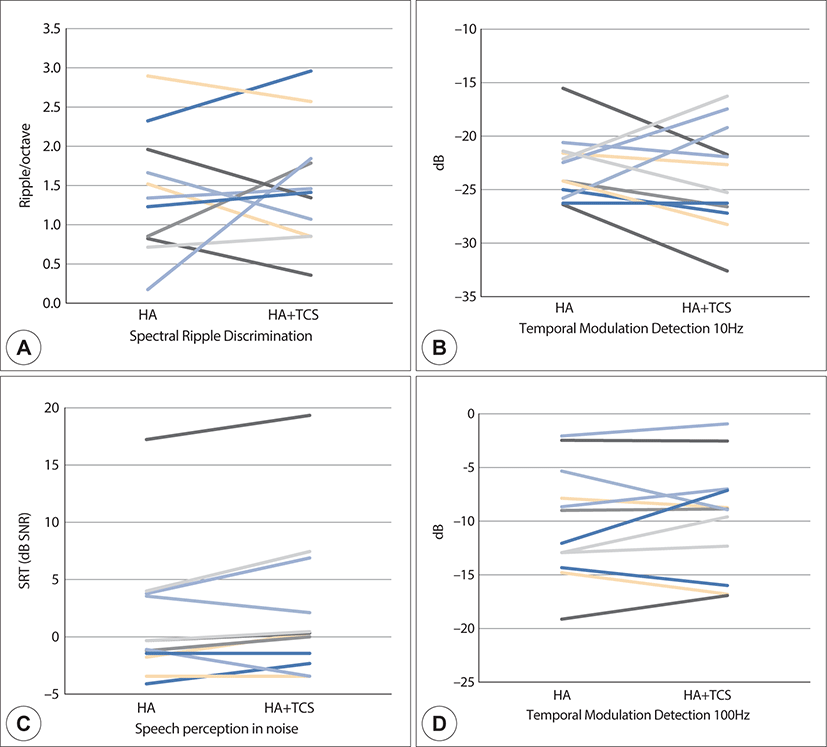
The comparisons of psychoacoustic test results for the HA-only and HA plus TCS conditions revealed no significant differences in the mean spectral ripple discrimination threshold (1.41±0.78 vs 1.50±0.78, respectively, Z=–0.178, p=0.859), TMD threshold at 10 Hz (−23.05±2.96 vs −23.79±4.79, respectively, Z=–0.623, p=0.533) and 100 Hz (−10.05±4.97 vs −9.65±5.17, respectively, Z=–0.667 p=0.505). However, the SRT in noise (i.e., poor speech perception) was significantly greater in the HA plus TCS conditions than in the HA-only conditions (2.70±6.49 vs 1.45±5.94, respectively, Z=–2.194, p=0.028, Fig. 2). Fig. 3 shows comparison of individual data for the three psychoacoustic tests. We also analyzed the correlations between SRTs in the HA plus TCS and HA-only conditions with various tinnitus characteristics, including subjective loudness, awareness time, duration, objective loudness, Tinnitus Handicap Inventory, and minimum masking level. However, the SRTs in both conditions were not significantly correlated with the tinnitus characteristics (p>0.05).
Discussion
This study has revealed that TCS from a built-in sound generator constrains the HA user’s speech perception ability in noise, implying that the TCS introduces additional noise to the existing tinnitus. The majority of studies of speech perception and tinnitus have demonstrated that tinnitus hinders speech perception, especially in noisy conditions,10–13) except for one recent study by Zeng et al.,14) who suggested that tinnitus does not impair the perception of external sounds. In a previous study performed by the author’s group, tinnitus constrained the subject’s speech perception in noise, without affecting the spectral or temporal resolution of hearing.11) The results imply that tinnitus may affect the central auditory system rather than the peripheral auditory system and may function as a central masker to degrade speech perception when individuals are listening to speech in the presence of background noise. Thus, it is hypothesized that if the TCS offsets the tinnitus, speech perception may improve under TCS conditions in individuals with tinnitus. However, the results of this study do not support this hypothesis. Rather, although TCS alleviates the discomfort of tinnitus, the loss of speech perception ability, as a function unique to HAs, is inevitable. Therefore, we recommend that individuals with tinnitus who use a HA with a built-in sound generator should turn off the sound generator in daily life, especially in a noisy environment.
In this study, the TCS did not affect auditory spectral resolution or temporal resolution. Auditory spectral resolution primarily depends on the active movement of outer hair cells15) and auditory temporal resolution is thought to be more strongly associated with central auditory processing than with auditory filtering.16,17) Because the TCS was set to a loudness similar to that of tinnitus (only 3.8±4.3 dB sensation level of the tinnitus loudness in this study), it seems likely that the loudness of the TCS was insufficient to affect the spectral and temporal resolutions significantly. In several studies that used the same psychoacoustic tests as this study, the SRT in noise tended to change more sensitively than the SRD and TMD.11,18) The auditory spectral and temporal resolution largely affected speech perception and there were strong correlations between the spectral or temporal resolutions and speech perception.19,20) However, in a study that evaluated the effects of HAs on the spectral and temporal resolutions, the HAs improved speech perception in noise without changing the auditory spectral and temporal resolutions.18)
Most receiver-in-canal HAs are now equipped with built-in sound generators, and the TCS help to control tinnitus in affected individuals, especially in quiet environments. Henry et al. compared the improvement in tinnitus between using HAs only and HAs plus built-in sound generators. After 3 months, the mean reduction in Tinnitus Functional Index showed a greater trend towards significance in the combination device users than in HA alone users. However, the reduction in the Hearing Handicap Inventory Score was not significantly different between the two groups.4) This suggests that the hearing benefit was not compromised by the addition of the TCS, in contrast to our results. However, hearing performance was evaluated by questionnaires in the study by Henry et al. rather than objective psychoacoustic tests, as in the present study. In another study, the relative efficacy of receiver-in-canal HAs, the same HAs with sound generators, and extended-wear, deep fit HAs (Lyric; Phonak, Stäfa, Swiss) on tinnitus control was evaluated. A clinically significant improvement in reaction to tinnitus was seen in all device groups, but these improvements did not differ across group.21) In a Cochrane review using three randomized controlled studies compared HAs with sound generator with HAs only in terms of the effect of reducing tinnitus, no difference was found (standardized mean difference –0.15, 95% confidence interval –0.52 to 0.22; 114 participants).22) However, research on the comparison of HAs with sound generator and HAs has been conducted very rarely, making it difficult to conclude yet.
There were several limitations of this study. First, the sample size was small due to the difficulty in recruiting subjects. Second, data for unilateral HA and bilateral HA users were combined. Therefore, we cannot completely rule out the possibility that some of the current results came out by chance, and further research using more sample size is needed in the future.
Conclusion
In individuals with tinnitus and hearing impairment, the TCS from the HAs constrained their speech perception ability in noise. This implies that the TCS introduces additional noise to the existing tinnitus, thus degrading the amplified speech signals generated by the HAs, even though the TCS can help alleviate the discomfort of tinnitus. Therefore, it is recommended that individuals with tinnitus who use a HA with a built-in sound generator should turn off the sound generator in daily life, especially in noisy environments.